Research Data Integrity Tool
Role:
Sole Designer
Team:
1 Designer, 1 CPO, 5 Engineers
Timeline:
2024
Contents:
Context, Problem, Outcome, My Role, Design Decisions
Research Data Integrity Tool
Role:
Sole Designer
Team:
1 Designer, 1 CPO, 5 Engineers
Timeline:
2024
Contents:
Context, Problem, Outcome, My Role, Design Decisions
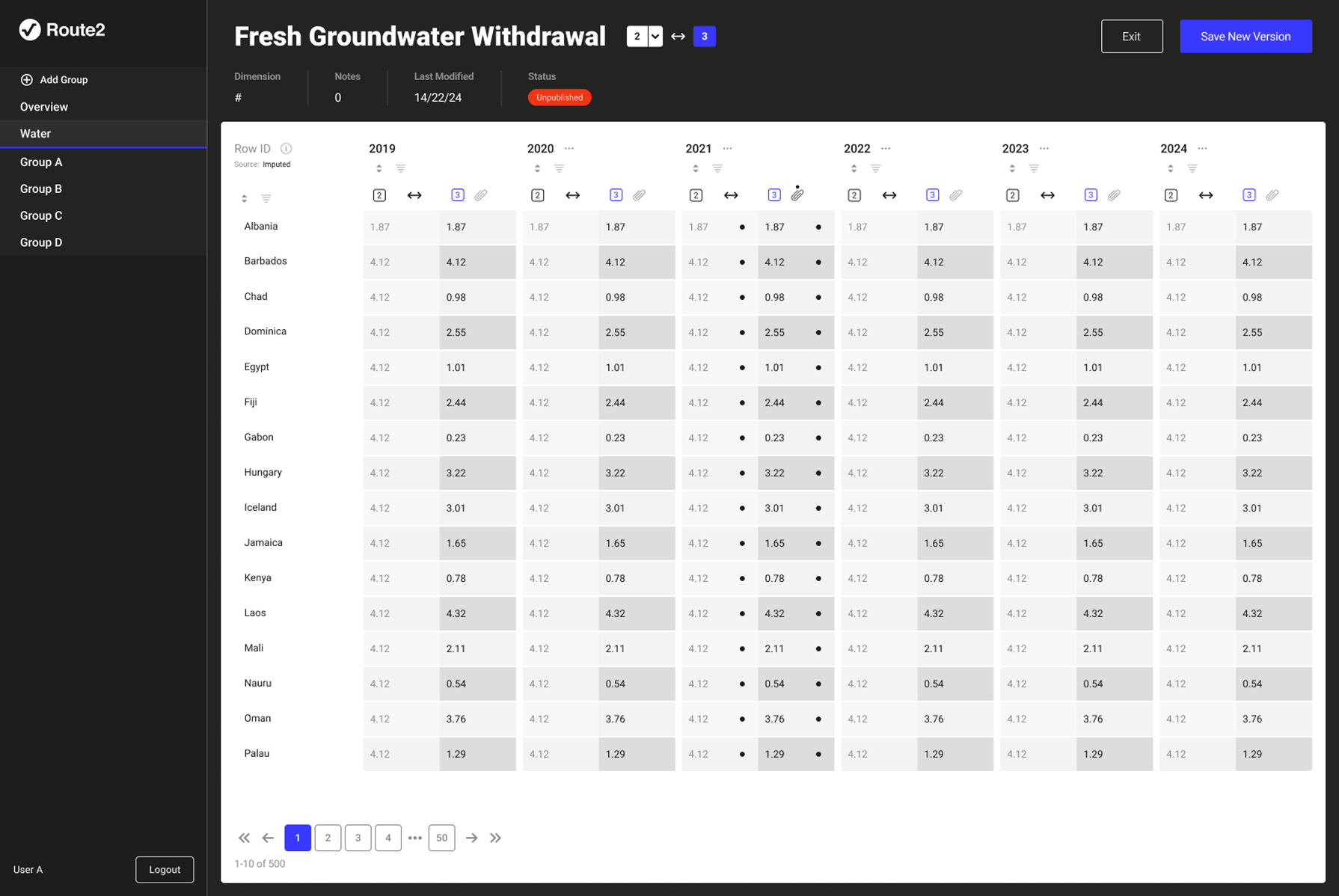
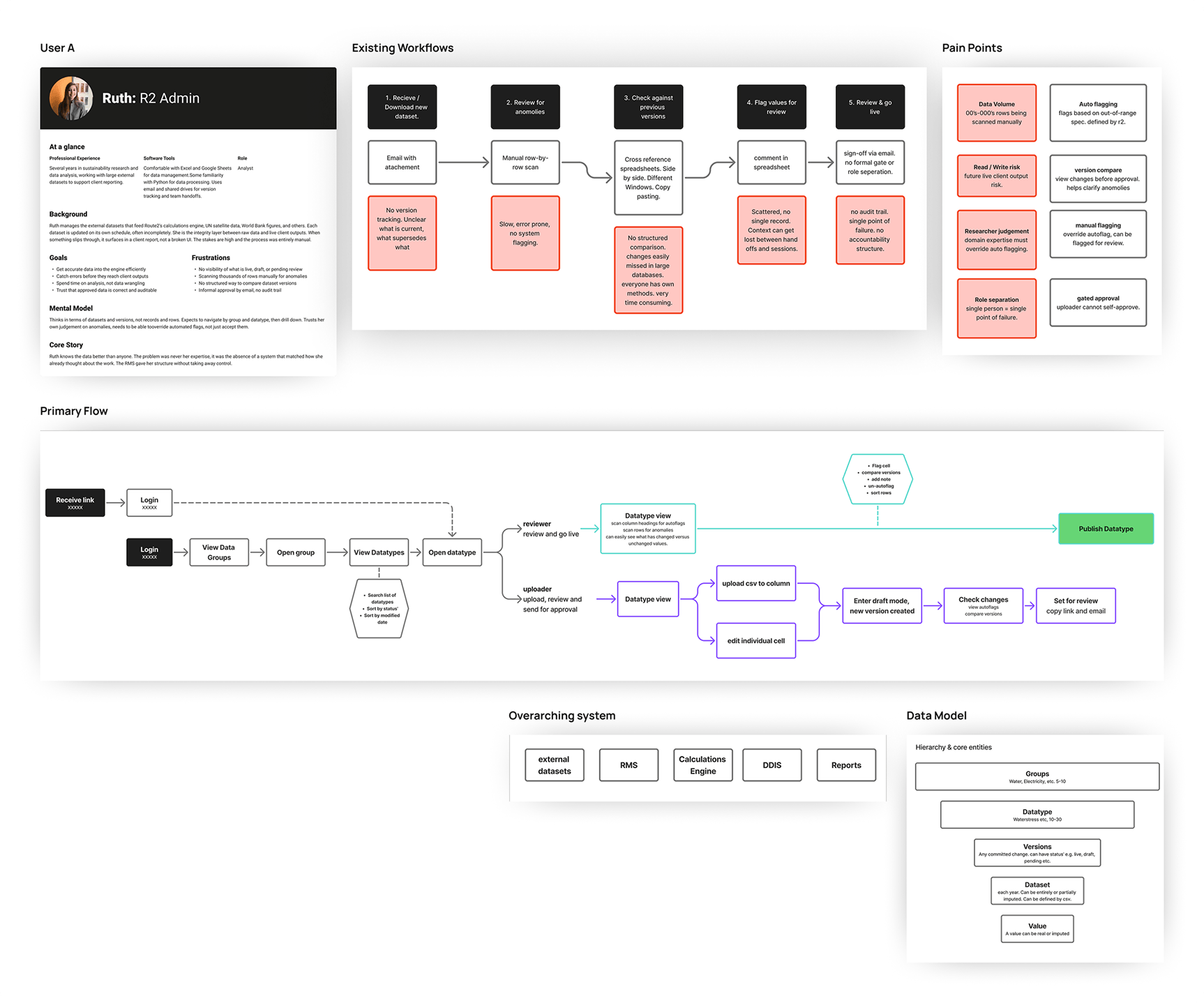
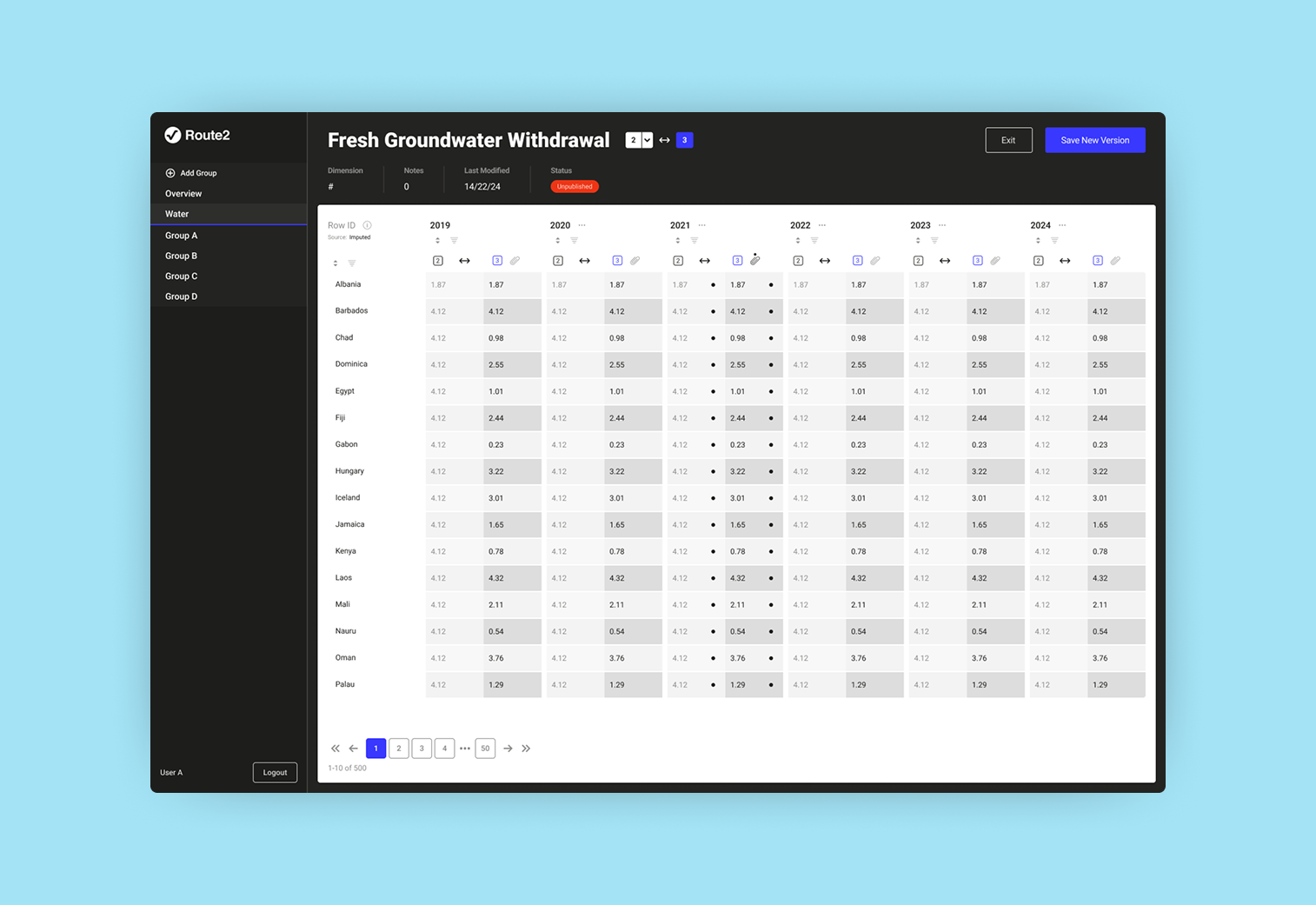
Route2 Sustainability; a consultancy built around a proprietary metric called Value2Society (V2S). The V2S output is powered by three interconnected systems: a data collection and management platform used by clients, a calculation engine that processes inputs into V2S scores, and a research management system that controls the external datasets feeding the engine. The RMS is the subject of this case study. The calculation engine is fed, via the RMS, by multiple external datasets each with their own release versions and update schedules. Researchers are the integrity layer between raw data and live calculations.
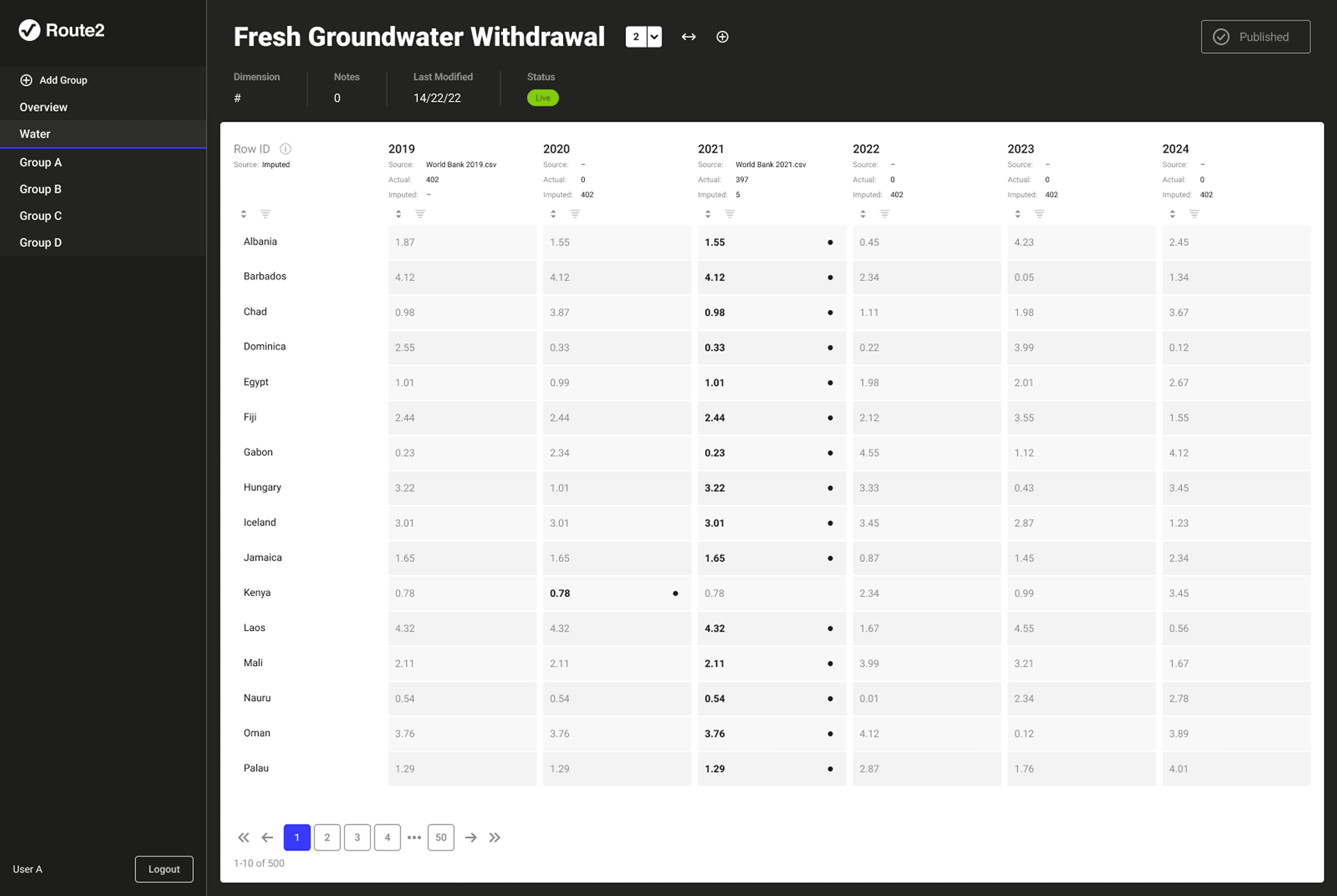
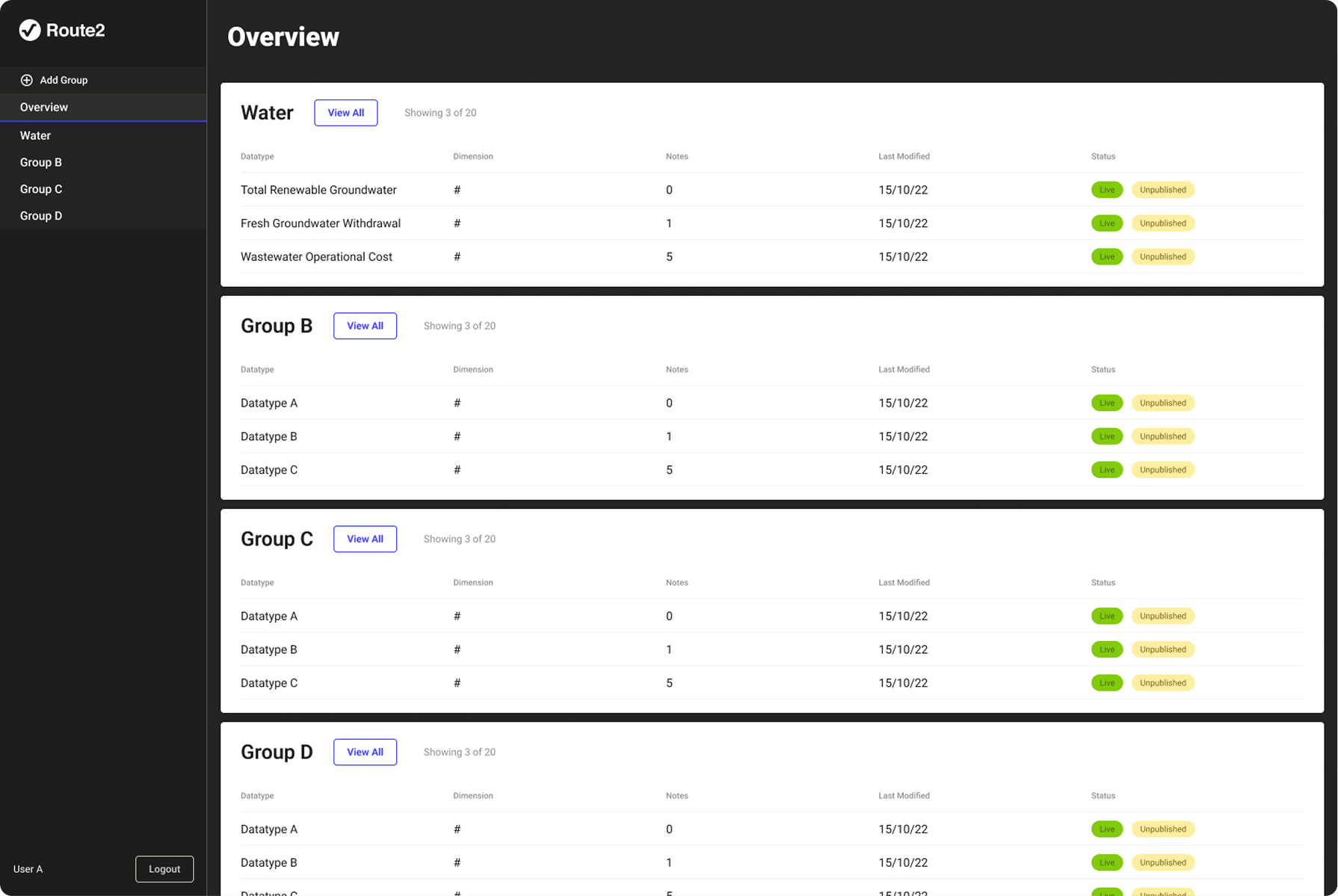
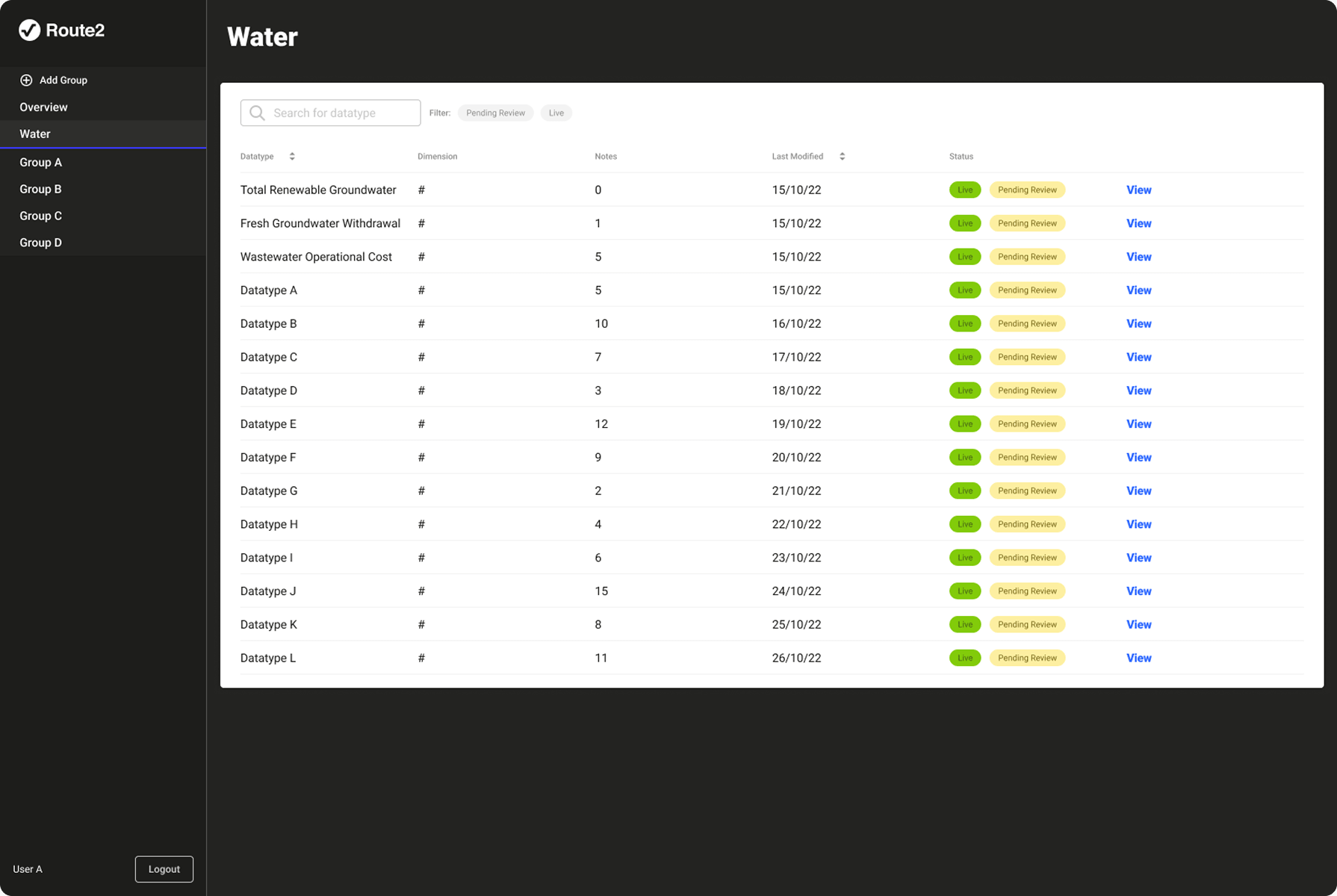
The data pipeline feeding Route2's calculation engine had no systematic visibility or control layer. Researchers were managing versioning, validation, and anomaly detection manually; tracking versions in spreadsheets, checking values by eye and correcting errors. A value could be technically valid but semantically wrong, within the right format but implausible in context. This was slow, error-prone, and consumed time that should have gone to generating insights. The consequence of getting it wrong was corrupted data in a live client report consuming further capacity to make corrections down the line.
An internal research management system that more than doubled researcher capacity, giving the team visibility and control over every dataset feeding the live calculation engine.